Делаю свою базу знаний
CHANGES
| VERSION | DATE | DESCRIPTION OF CHANGE AUTHOR |
|---|---|---|
| 0.05 | 2026.04.10 | Добавлено определение zag Файл журнала (log.podlite) со структурой и полями |
| 0.04 | 2026.04.09 | Добавлен глоссарий: zag Источник, Экстракт, Слой извлечения, Таксономия доменов, Индексный файл, Приём, Проверка |
| 0.03 | 2026.01.07 | Добавлена глава об zag AxonaCloud - сервисе облачного хранения и оркестрации |
| 0.02 | 2022.06.30 | Описание компонент базы zag знаний |
| 0.01 | 2020.06.04 | Начальная версия zag |
TODO
уточнить протокол синхронизации локального стэйта и облачного
протокол p2p между узлами
Основные положения
Компоненты
База знаний это прежде всего набор текстовых файлов, расположенных на локальной файловой системе пользователя.
Аксона — приложение для графического представления, внесения изменений, анализа и накопления информации расположенной в как в локальной файловой системе, так и подключаемых удаленных баз знаний других пользователей.
Для доступа к базе знаний с других устройств, например с планшета или смартфона, используется сервис облачного хранения базы знаний axonaCloud. Этот сервис представляет собой self-hosted решение и взаимодействует с приложением Axona c помощью протокола синхронизации.
Благодаря такой схеме пользователь может продолжать вносить изменения в базу знаний с других устройств.
Сервис облачного хранения позволяет устанавливать связи и обмениваться информацией с аналогичными сервисами других пользователей.
Сервис облачного хранения также осуществляет публикацию базы знаний в виде HTML. Это возможно как с помощью встроенного web сервера, так и с помощью сторонних сервисов. Например: vercel.
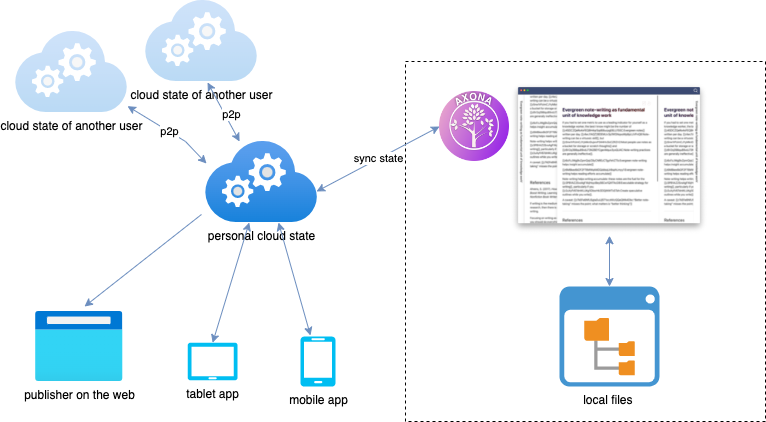
Компоненты персональной системы знаний
Текстовая природа файлов позволяет использовать любой текстовый редактор для внесений изменений, а так же набор любых других утилит командной строки.
AxonaCloud — сервис облачного хранения и оркестрации
AxonaCloud представляет собой self-hosted платформу для синхронизации базы знаний между устройствами и автоматического развертывания инфраструктуры на основе описаний в файлах базы знаний.
Ключевая инновация AxonaCloud: Documentation = Infrastructure. Нет разрыва между документацией и реальностью. Что описано в файлах базы знаний — то и работает в production.
Основные компоненты
Синхронизация — использует Syncthing для P2P синхронизации между устройствами без центрального сервера
Оркестрация контейнеров — автоматическое развертывание Docker контейнеров из блоков кода в файлах базы знаний
Сетевая инфраструктура — управление WireGuard VPN, Nginx и Pi-hole через конфигурации в markdown
Автоматизация — интеграция с n8n для создания workflow'ов, управляемых из базы знаний
Публикация — автоматическая публикация статических сайтов на Vercel и других платформах
Мобильный доступ — iOS/Android клиенты с режимом "только чтение" для безопасного доступа к базе
Развертывание из кода в документах
Одна из ключевых возможностей AxonaCloud — автоматическое развертывание инфраструктуры на основе блоков кода, описанных непосредственно в файлах базы знаний.
Пример:
# services/analytics.md ## Plausible Analytics Используем privacy-friendly аналитику для сайтов. Z<>=begin code :id<reset> :dockerImage<'docker:27-cli'> #!/bin/sh echo " - Docker: $(docker --version 2>/dev/null || echo 'Not available')" Z<>=end code
AxonaCloud парсит такие блоки и автоматически разворачивает соответствующие контейнеры. Это обеспечивает единый источник правды — документация всегда отражает реальное состояние инфраструктуры.
Варианты развертывания
AxonaCloud может работать на различных типах устройств:
Raspberry Pi (4GB+ RAM) — домашний сервер, edge computing
Mini PC (Intel NUC и аналоги) — инфраструктура для малого офиса
Ноутбук — для разработки, тестирования, мобильных сценариев
VPS (DigitalOcean, Hetzner и др.) — публично доступные сервисы
Облако (AWS, GCP, Azure) — enterprise deployments
Пользователь может выбирать, какие компоненты запускать на каком устройстве в зависимости от доступных ресурсов и требований.
Целевая аудитория
DevOps-инженеры / SRE — инфраструктура описана в тех же файлах, что и design docs
Indie Hackers / Solo разработчики — простое развертывание сайтов, backend и мониторинга
Малые команды разработки (5-20 человек) — база знаний становится production infrastructure
Self-hosters / энтузиасты приватности — управление домашней инфраструктурой через markdown/podlite
Исследователи / академические работники — автоматизация data pipelines без глубоких DevOps знаний
Организация файлового хранения
Основной елемент базы знаний — текстовый файл. Организуются файлы в каталоги. Каких то правил для именования файлов и каталогов нет. Владелец вправе самостоятельно организовывать структуру каталогов и придумывать правила именования файлов.
По идее формат может быть любым, например pdf. Главное что бы можно было легко извлекать из такого файла информацию для поиска и производить открытие этого файла. Возможно со временем будет добавлена поддержка файлов, отличных от текстового формата.
Итак, для начала будем пока рассматривать только текстовые файлы. Ничто не мешает хранить в структуре файлов другие типы файлов. Например, те же pdf, картинки. Но какая-то интерпретация содержимого таких файлов на начальном этапе будет отсутствовать.
Приведу для наглядности часть такой структуры:
├── 20200310 │ ├── 01-note.pod6 │ ├── 02-note.pod6 │ └── media │ └── image1.jpg └── 20200311 ├── 01-note.pod6 ├── 02-note.pod6 ├── 03-note.pod6 └── media └── diagram.jpg
В именах каталогов содержится дата — указание на конкретный день,
а содержимое каталогов — заметки, сделанные в течении дня.
В каталоге media находятся
дополнительные материалы: изображения.
Указанным в примере способом можно организовать статьи для блога или просто заметки.
Для больших документов, в которых есть заголовок с изменениями — изменения экспортируются в основную ленту активности. Сопровождаются ссылкой на страницу документа.
Все ссылки, которые ссылаются на локальные файлы, заменяются на абсолютные, возможно сокращенные.
Если документ не является постом или заметкой и у него нет адреса для публикации, то адресом принимается его относительный путь в файловой системе.
Глоссарий
- Источник (10-sources/)
- Сырой материал для извлечения знаний: книги, статьи, транскрипты, голосовые заметки.
Неизменяемый после захвата — ничто не модифицирует файл-источник. Каждый источник имеет
карточку с
:type('book-card')содержащую метаданные и заметки.
- Экстракт
- Атомарный файл знания, содержащий один концепт, модель, антипаттерн или actionable-инсайт.
Размечается
:type('extract'),:extract-type(),:domain(),:source(). Одна идея — один файл. Гранулярность захвата равна гранулярности извлечения. См. P88.
- Слой извлечения (10-extracted/)
- Коллекция экстрактов, классифицированных атрибутом
:domain(). Таксономия доменов и каталог хранятся вindex.podlite.
- Таксономия доменов
- Классификация экстрактов по контексту применения. Хранится как блок
=data :id<taxonomy>вindex.podlite./ingestчитает таксономию доменов перед разметкой — использует только существующие домены./lintвалидирует: неизвестный:domain()= ошибка.
- Индексный файл (index.podlite)
- Каталог слоя извлечения. Содержит таксономию доменов, каталог страниц и статистику в виде
=dataблоков. LLM читает этот файл при старте сессии вместо сканирования всех файлов. Используется/ingestдля разметки,/lintдля валидации.
Структура:
=begin data :id<taxonomy>
domain,description,question
strategy,"позиционирование, конкуренция","где играть и как победить?"
=end data
=begin data :id<pages>
file,title,extract-type,domain,source
wardley-evolution-axis,Ось эволюции компонентов,model,strategy,wardley
=end data
=begin data :id<stats>
domain,count
strategy,42
=end data
- Приём (Ingest)
- Операция превращения источника в экстракты. Классифицирует тип источника, разбивает
на главы, извлекает атомарные концепты, проверяет дубликаты, показывает человеку на
одобрение. Реализована как скилл
/ingest.
- Проверка (Lint)
- Операция проверки здоровья слоя извлечения. Обнаруживает противоречия между экстрактами,
устаревшие факты, orphan-страницы, отсутствие provenance, низкую уверенность. Генерирует
контраргументы. Реализована как скилл
/lint.
- Файл журнала (log.podlite)
- Append-only хронологический журнал всех операций wiki (ingest, lint, query, update).
Хранится как блок
=data :id<operations>вlog.podlite. LLM читает последние записи при старте сессии чтобы понять что изменилось. Обеспечивает audit trail, анализ паттернов и recovery. Никогда не редактируется — только дополняется.
Структура:
=begin data :id<operations>
timestamp,op,pages-touched,score,details
2026-04-10T09:15:00,ingest,3,—,"source=ramanujam, 12 sections, 12 extracts created"
2026-04-10T10:30:00,lint,150,health=87,"3 contradictions, 7 orphans, 2 stale"
2026-04-10T11:00:00,query,5,—,"audience validation → 5 extracts retrieved"
=end data
Поля:
timestamp— когда операция запущена (ISO 8601)op— тип операции: ingest, lint, query, update, deletepages-touched— количество затронутых файловscore— health score для lint, confidence для ingest, прочерк иначеdetails— свободный текст с контекстом